Java Quartz and RDS
Quartz Scheduler brought down our RDS
A few weeks ago, we started seeing unusual CPU spikes on our RDS instance. Jobs that were supposed to run weren't running. The system was alive, instances were healthy, logs were clean — but nothing was executing. Triggers were piling up silently.
Our stack at the time was straightforward. Java with Spring, Quartz Scheduler using JDBC JobStore backed by RDS Postgres, three scheduler nodes all pointed at the same database. The idea was solid — jobs survive restarts, multiple nodes coordinate through the DB, no single point of failure. We set it up, it worked in staging, we shipped it.
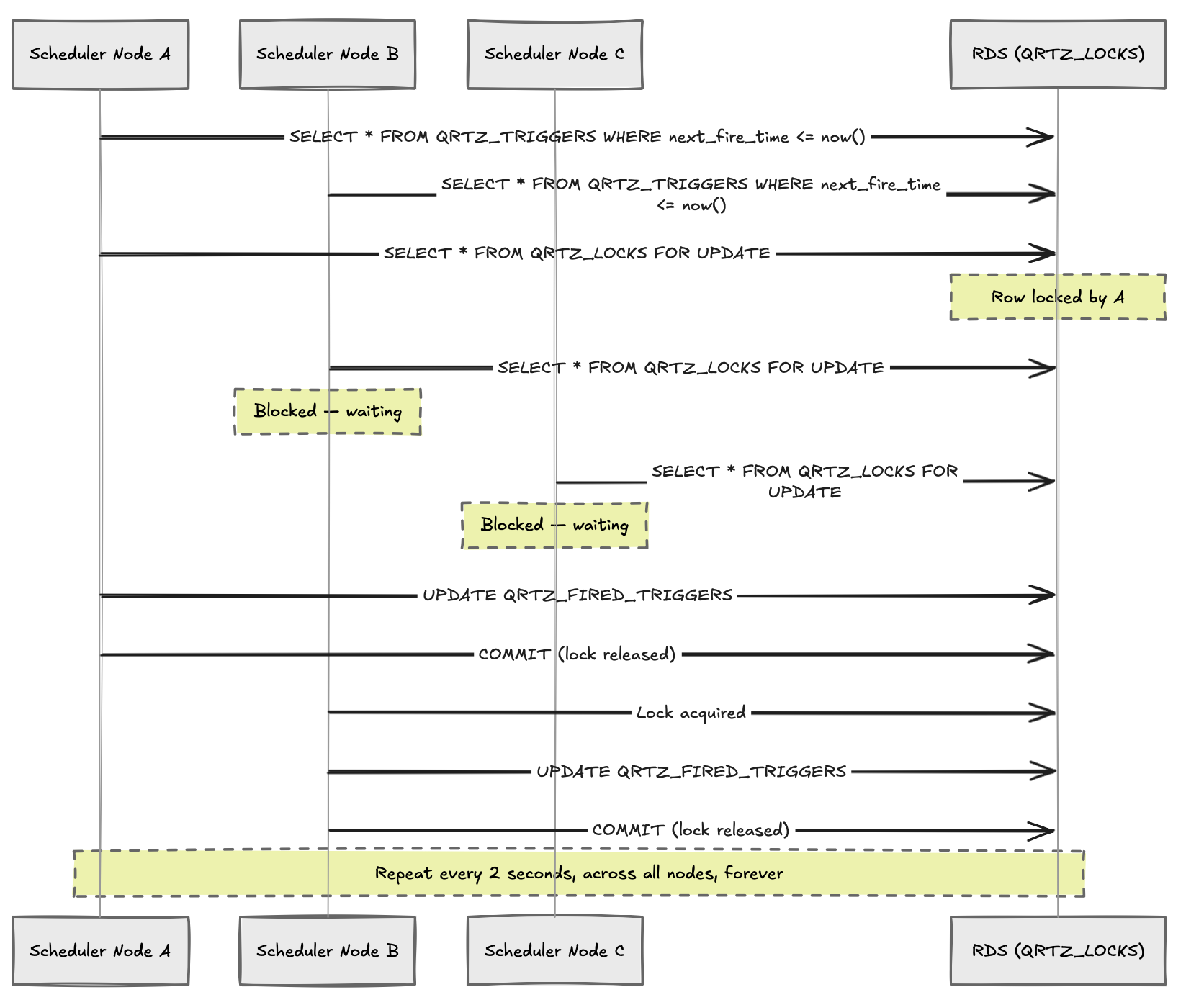
Quartz's JDBC JobStore creates a handful of tables — QRTZ_TRIGGERS, QRTZ_JOB_DETAILS, QRTZ_FIRED_TRIGGERS, QRTZ_LOCKS — and uses them as a coordination layer between nodes. Each scheduler node polls the database continuously, acquires row locks, updates trigger states, checks for misfires. With one node this is manageable. With three nodes polling every two seconds, it becomes something else entirely.
The incident happened after we deployed a new workflow feature. Each user action would schedule a handful of delayed jobs — emails, retries, timeout checks. Nothing unusual. But the job count grew quietly over a few days, and then one evening the polling storm began. Each node was doing SELECT ... FOR UPDATE on QRTZ_LOCKS, updating trigger rows, checking misfires, updating QRTZ_FIRED_TRIGGERS — thousands of times per minute. Within ten minutes we had crossed two million queries. The RDS instance hadn't crashed, but connection pools were saturated, row locks were piling up, and the scheduler nodes were effectively blocking each other into a deadlock. No job executed for nearly forty minutes before we caught it.
The fix that night was blunt — we brought down two of the three scheduler nodes, reduced polling frequency, and let the backlog drain. That bought us time.
We didn't give up on Quartz immediately. The more embarrassing part of this story is what came next.
The first instinct was to blame MySQL. We were on RDS MySQL at the time and row locking behavior in InnoDB under high contention is notoriously unpleasant. Someone pulled up a Stack Overflow thread from 2013 where a person with a similar problem had switched to Postgres and seen improvements. That was enough justification for us. We migrated.
The migration took a weekend. Schema conversion, driver swap, testing, deploy. Quartz has official DDL scripts for both MySQL and Postgres, so that part was clean at least. We tuned max_connections, set reasonable lock_timeout values, and felt cautiously optimistic.
Two weeks later, the same thing happened. Different error messages in the logs — Postgres surfaces lock contention differently than MySQL — but the same outcome. Connection pool exhausted. Triggers backed up. Jobs not running.
At this point someone suggested Aurora. Aurora was relatively new then, but the pitch was compelling — MySQL-compatible, distributed storage, better read scaling, faster failover. Maybe the underlying storage engine would handle concurrent writes more gracefully. We moved again.
Aurora did handle the load better for a while. Failover was faster when we tested it. The CloudWatch metrics looked healthier. We convinced ourselves we had fixed it.
Then we shipped another batch of workflow jobs. Same polling storm. Same lock contention. Same pile of unexecuted triggers.
Three databases. Same problem each time. That's when it became clear the database was never the issue. Quartz's coordination model was the issue, and no amount of engine-swapping was going to change that. SELECT ... FOR UPDATEon a hot lock row is SELECT ... FOR UPDATE on a hot lock row whether it's MySQL, Postgres, or Aurora underneath. Quartz is well-suited for daily cron jobs, report generation, small batch workloads on a single node. The JDBC cluster mode is designed for failover, not for high-throughput coordination. When you treat the database as a distributed lock manager under real load, you're going to find its limits. SELECT ... FOR UPDATE across multiple competing processes doesn't scale the way you'd hope.
We ended up rewriting the scheduler. The replacement was a small Clojure service using MongoDB, where workers would claim jobs using a single atomic findAndModify query — no joins, no global lock tables, no polling storms. The database load dropped significantly. The new scheduler has been running since without incident.
The incident forced me to revisit how distributed coordination actually works, and where the abstraction breaks down. A shared relational database can coordinate processes, but it was never meant to be a high-frequency lock server. The table name QRTZ_LOCKS is a hint that should have made me more cautious when we added the second and third nodes.
Better practices would have caught this earlier. Load testing the scheduler with realistic job volumes, monitoring lock wait times on RDS, and being skeptical of clustering modes in libraries not originally designed for them. These seem obvious in retrospect.
The scheduler now runs quietly. Nobody talks about it. That's usually the sign it's working.